A Bibliographic Survey of Neural Language Models


Abstract
This text corresponds to a reduced and adapted version of our previous Technical Report [https://www.ic.unicamp.br/~reltech/2024/24-01.pdf] submited to the Institute of Computing (IC) of UNICAMP (Universidade Estadual de Campinas).
This text presents a literature review of Language Models (LM), covering two main topics: (1) The Transformers-based Neural Network used to train modern language models; and (2) The Semantic Space produced by the network training of the LM, which computationaly represents the language being modeled.
In fact, obtaining such a computational representation for textual constructs is a long-standing problem that has challenged diverse NLP (Natural Language Processing) approaches. The establishment of transformers-based language models opens up vast possibilities and perspectives on interdisciplinary topics beyond NLP.
Therefore, this survey details the history, the development and the mechanisms of Transformers-based language models. The text concludes with a critical analysis addressing issues regarding applications based on language models.
This post is a shortened and adapted version of a previously published article released as a technical report by the Institute of Computing at the University of Campinas: https://www.ic.unicamp.br/~reltech/2024/24-01.pdf . The original report contains additional details, discussions, and references that were condensed here for readability and accessibility.
1. Introduction
Natural Language Processing (NLP) is a field of Computer Science whose goal is to convert human language into a representation that is interpretable by computers. It is an interdisciplinary research area that incorporates concepts from various other fields, such as Statistics and Linguistics.
Manning and Schütze, 1999 classify NLP methods into statistical and non-statistical approaches. Statistical approaches rely on patterns that commonly occur in a language, while non-statistical approaches focus on mapping and computationally implementing the rules that structure the language. The distinction between statistical and non-statistical approaches has roots grounded in the philosophical debate surrounding the perspectives of Rationalism and Empiricism [Manning and Schütze, 1999].
In the epistemological realm [Barlas and Carpenter, 1990], Rationalism claims the ideas of deductive reasoning are possible because they are innate, prior to all experience. In turn, Empiricism states that none of our ideas are innate, and the mind would be a blank tablet when we are born. Subsequently, Kant considered both the concept of active mind (from rationalism) and the role of sensations (from empiricism) as essentials in knowledge acquisition. In turn, Bertrand Russell "explicitly rejected the existence of innate ideas". The debate remains open and has led to the development of several philosophical schools.
In the field of Linguistics, the rationalist perspective is characterized by the belief in the existence of an innate language fixed in the human brain through genetic inheritance. Advocated by Noam Chomsky [Manning and Schütze, 1999], rationalism has been crucial to the development of the theory of Formal Languages, which serves as the foundation for current programming languages. Formal languages constitute a special class of language that lacks ambiguity and, therefore, can be interpreted/compiled by computers. The ability to interpret a language in a non-ambiguous manner is essential for a computer to execute commands instructed by humans through a source code [Manning and Schütze, 1999].
In contrast to programming languages, natural languages are inherently ambiguous, since a word or phrase can have more than one meaning [Goertzel, 2013]. In natural language cases, the empiricist perspective assumes that, instead of pre-constructed linguistic structures, the human mind possesses generic operations of association, generalization, and pattern recognition. These cognitive abilities, combined with a rich sensory system, enable humans to learn detailed language structures. This hypothesis forms the basis of Machine Learning methods that use statistical models to recognize patterns and complex structures in a dataset. This statistical approach is grounded in the Information Theory developed by Claude Shannon [Manning and Schütze, 1999].
Manning and Schütze, 1999 point out that "the difference between the approaches is not absolute but one of degree", as rationalism believes "the key parts of language are innate – hardwired in the brain at birth as part of the human genetic inheritance" while empiricism believes in an innate capacity to develop language through generalizations such that "a baby’s brain begins with general operations for association, pattern recognition, and generalization, and that these can be applied to a rich sensory input available to the child to learn the detailed structure of natural language".
This philosophical debate remains an open question; however, its practical utility is valuable as it theoretically underpins various areas of computer science.
More recently, statistical approaches have advanced the state-of-the-art in various NLP tasks. This progress can be attributed to, among other factors: (1) advances in computational capacity; (2) recent deep neural network models capable of retaining significantly more information than previously proposed neural models; and (3) the development of more efficient techniques for handling the vast amount of information available on the Web.
The rest of this text is organized as follows: sections 2 and 3 give some background on foundations of Neural Networks, Deep Neural Networks, Transformers, as well as the history and development of the so-called Neural Language Models. Sections 4 and 5 review related work of two case studies that involve neural networks and transformers: Topic Modeling and Semantic Annotations of virtual patients. Section 6 briefly discusses more recent work developed in research in Language Models. This is followed by a section that critically analyzes language models addressing some interdisciplinary aspects, finishing with concluding remarks.
2. Deep Neural Networks
Several recent advances in the field of Natural Language Processing (NLP) are attributed to the mellowing of Deep Neural Network models, which are more sophisticated types of Artificial Neural Networks. This section describes some relevant issues in Neural Network architectures, followed in the subsequent section by Language Models in the context of such networks
2.1 Artificial Neural Networks
An artificial neural network — a computational abstraction inspired by the biological nervous system — is an interconnected network of artificial neurons organized in layers. Typically, neural networks perform Supervised Learning, where the network receives successive sets of pre-labeled training samples and must infer the corresponding output for each input sample. For example, a neural network can be trained to recognize cancerous tumors in computed tomography images based on labeled images previously presented to the model. After this training phase, the neural network is capable of making inferences about new images that were not observed by the model during its network training [Kubat, 2017] .
Example - Sentiment Analysis through Neural Networks
Sentiment Analysis through neural networks is an NLP task whose objective is to classify sentences based on their sentiment polarity C={Positive, Negative, Neutral}. In the training phase, iteratively the network is fed by pairs of sentences and labels, in the format [sentence,label] contained in the training set. In each training step, let s be the sentence to be classified, y the corresponding label, and h the output of the classification, representing the class inferred for s by the algorithm. The sentence s is represented by a feature vector $x=(x1, x2, ..., x_n)$. Let $\theta = (\theta_1,\theta_2,...,\theta_{m})$ be a vector of parameters (weights) of each neuron.
Classification works as follows. Vector x is propagated through the network's layers, adjusting the parameters $\theta$ of each neuron based on their contribution to constructing the output y.
Disclaimer: Here, expressions enclosed by
$ $represent mathematical equations that were incorrectly rendered by the website. Interested readers can refer to the original paper [Pantoja et al., 2024] for the properly formatted equations.
Figure 1 illustrates a neural network classifying the sentence "I liked this movie". The neural network produces an output vector o=(o1, o2, o3) containing the algorithm's hypotheses regarding the probabilities of the sentence belonging to each of the possible classes in C, where the highest one is chosen as the algorithm’s hypothesis h=positive.
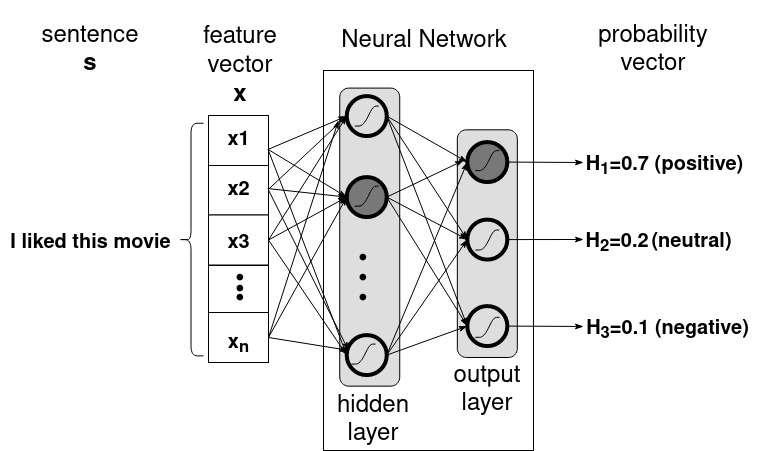 Figure 1: Neural network performing sentiment analysis. Adapted from [Kubat, 2017].
Figure 1: Neural network performing sentiment analysis. Adapted from [Kubat, 2017].
Each neuron in the network has a transfer function (or activation function) f(\Sigma) that operates on the weight parameter \theta_{i} of the neuron and the input feature $x_{i}$, as illustrated in Figure [2].
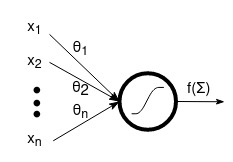 Figure 2: The mechanics of an artificial neural unit..
Figure 2: The mechanics of an artificial neural unit..
Here, several transfer functions could be employed, including the sigmoid function:
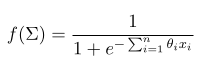 Figure 3: The sigmoid equation.
Figure 3: The sigmoid equation.
During this training phase, each sentence is fed and processed in a training step. A training step of a neural network involves two main mechanisms [Kubat, 2017]:
-
Forward Propagation: Propagates the sample sentence
sthrough the neural network until it reaches the final layer. The final layer produces the hypothesishcontaining the probability ofsbeing classified aspositive,neutralornegative. The difference between the hypothesishinferred by the algorithm and the true classyannotated in the training set indicates the contribution (or responsibility) of each parameter$\theta_i$to the error measured when classifyings. -
Backpropagation: Adjusts each parameter
$\theta_i$\based on its contribution to the error calculated between the hypothesishand the true classyannotated in the training set. The larger the contribution of the neuron, the greater the adjustment in its parameters should be. The magnitude of the adjustment in the parameters$\theta_i$can be controlled by the hyperparameter$\eta$, which typically has a value close to 0.1.
Hyperparameters are variables that control the overall behavior of the network. Do not confuse with the term "parameter" that refers to the weights assigned to each neuron in the network.
The algorithm completes one training epoch when it processes all the samples in the training set. The number of epochs is also a hyperparameter. At the end of the training, the network parameters have been calibrated to solve the task for which it was trained Kubat, 2017].
An architecture with at least one hidden layer of neurons (as depicted in Figure [1] is known as a Multi-Layer Perceptron [Kubat, 2017]. Other models implement different architectures, transfer functions, propagation mechanisms, etc. Deep neural networks models serve more robust architectures, including Recurrent Neural Networks, Convolutional Neural Networks, and the more recently introduced Transformers.
2.2.1 Recurrent Neural Networks
A recurrent neural network is suitable for solving problems with a sequential aspect [Ruder, 2019], as observed in various NLP problems (e.g., sentiment analysis, Named Entity Recognition (NER), etc.). Recurrent neural networks leverage the inherent sequential aspect in textual constructs. Broadly speaking, the sequential aspect implies that each term $w_i$ in a given sentence s depends on the preceding term $w_{i-1}$s. For example, for a neural network handling the sentence "She is excellent at her role as a", the probability of the next word being "doctor" is immensely higher than being "and" [Thrampoulidis, 2024], as illustrated by the Equation [1].
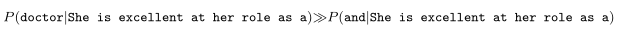 Equation 1: The sequential aspect.
Equation 1: The sequential aspect.
The Long-Short Term Memory (LSTM) model [Hochreiter and Schmidhuber, 2024] is a sophisticated type of recurrent neural network that achieves considerable success in addressing NLP problems due to its mechanism for deciding which information to retain and which to discard [Ruder, 2019]. Thus, the LSTM is capable of capturing contextual information from terms that are distant from the term being currently processed. However, the LSTM experiences performance degradation in scenarios involving very long sentences. This issue is known as Long-Term Dependencies, which arises when a word depends on words that are far apart in the sentence.
The LSTM has unidirectional contextual memory, restricting its usage to acquiring information solely from preceding terms (in the case of the left-to-right version of LSTM) or solely from subsequent terms (in the right-to-left LSTM) [Devlin et al., 2018]. Additionally, as a specific type of recurrent neural network, the LSTM faces several challenges during the training phase, such as gradient explosion and gradient vanishing [Pascanu et al., 2013]. Furthermore, the sequential nature of the LSTM precludes the parallelization of the training process [Vaswani et al., 2013].
Despite these limitations, LSTM is often successfully employed in the Sequence Translation (or sequence-to-sequence) task, which aims to transform a given sequence s of arbitrary length into a corresponding sequence t of pre-defined fixed size n [Sutskever et al., 2014]. This fixed-size representation can be used to perform other NLP tasks (e.g., Language Modeling, Machine Translation, Speech Recognition, Question-Answering) through Transfer Learning techniques.
A significant advancement in this sequence-to-sequence task (and consequently in the NLP research field) was accomplished by the Transformer, a novel deep neural network model that overcomes the issue of long-term dependencies and provides a means to obtain bidirectional contextual memory. The next section focuses on the Transformer.
2.2 Transformers
The Transformer model, introduced in the paper "Attention is All You Need" [Vaswani et al., 2013], addresses the sequence-to-sequence problem more efficiently than the LSTM. The Transformer is a deep neural network model that captures the context through the Attention Mechanism. With this mechanism, the Transformer has advanced the state-of-the-art in NLP tasks that can be modeled as an instance of the sequence-to-sequence problem.
2.2.1 The Attention Mechanism
The Transformer model overcomes the issue of long-term dependencies through the attention mechanism, which can capture global dependencies in the input sentence regardless of the distance between words [Vaswani et al., 2013]. Thus, this model can encode the context of the input sentence into the vector representation produced as output. The attention mechanism provides the Transformer with the ability to focus on words that are relevant to achieving the goal of the task being performed.
There are various attention mechanisms [Luong et al., 2015][Galassi et al., 2015]. The Transformer specifically employs Self-Attention (or Intra-Attention), which involves a weighted sum of vectors resulting from successive linear transformations of the matrices Q, K, and V (query, key, and value, respectively) [Kobayashi et al., 2020].
Matrices K and V comprehend the Neural Memory [Geva et al., 2020][Sukhbaatar et al., 2019] in which each row corresponds to a word (although, in other settings, it could be a character, a sentence, etc) within the training set, and the columns hold the distribution of weights [Galassi et al., 2015] learned by the network. This distribution accounts for the context learned during the training phase. According to [Geva et al., 2020], "each key vector $k_{i}$ captures a particular pattern (or set of patterns) in the input sequence, and that its corresponding value vector $v_{i}$ represents the distribution of terms that follows said pattern".
In fact, initially Geva et al., 2020 showed the Feed-Forward sublayer can be seen as a neural memory, and Sukhbaatar et al., 2019 claimed a Feed-Forward sublayer can be seen as an attention layer, therefore we extend the concept of neural memory to refer also to the attention layer.
The core of an attention mechanism is the computation over the matrices K, Q and V to infer an appropriate context representation. In each training step, the current word being processed (the query q) is matched against the K and V matrices to search for a key-value pair corresponding to the given query q. In this training process, the matrices undergo the series of operations illustrated in Figure [4], which is a visual representation of the attention function in Equation 2 to map a query and a set of key-value pairs into an output [Vaswani et al., 2013]. Here, we use the notation c to refer to this output vector.
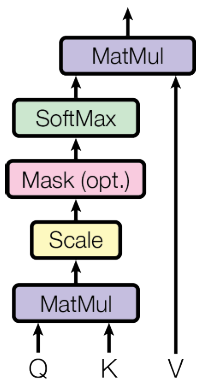 Figure 4: Operations performed by the layers of Self-Attention on the matrices
Figure 4: Operations performed by the layers of Self-Attention on the matrices Q, K, and V. Source: [Vaswani et al., 2013].
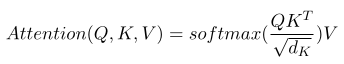 Equation 2: Attention equation.
Equation 2: Attention equation.
The attention mechanism operates over the K, Q, and V matrices in order to highlight the prominent patterns observed in the training dataset. The mechanism is about matching the context of a query q (the context of the given sentence) against the most similar context accumulated on the neural memory of {K,V} whereupon the network gets information to accomplish the demanded task (e.g., the translation task in the original Transformer model [Vaswani et al., 2013]). As a byproduct of translation, the attention mechanism generates word alignments [Luong et al., 2015.
As an example, Figure 5 shows an alignment matrix derived from translating an input sentence (in the column) from English to German (in the rows). This matrix helps to visualize how the attention gets the correspondences between all words in a sentence: it highlights the "attention" each word in the target sentence pays to the words in the source sentence.
 Figure 5: Word alignments derived from a translation task from English to German. Source: [Luong et al., 2015.
Figure 5: Word alignments derived from a translation task from English to German. Source: [Luong et al., 2015.
The original Transformer architecture (Figure 6) consists of two stacks of N layers of Encoders and Decoders. Subsequent research proposed different architectures [Tian et al., 2024], for example encoder-only such as BERT [Devlin et al., 2018], and decoder-only such as GPT [Radford et al., 2018].
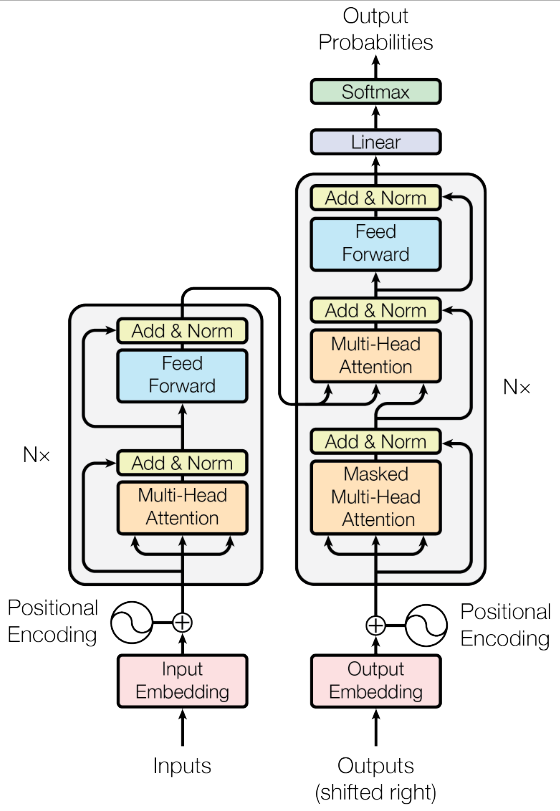 Figure 6: Transformer architecture. Source: [Vaswani et al., 2013].
Figure 6: Transformer architecture. Source: [Vaswani et al., 2013].
2.2.2. Encoders
An Encoder correlates each word $p_i\in s$ with all other words in the sentence s.
Its result is a fixed-size vector representation c that encapsulates information regarding the sentence context.
The input sequence flows through the N layers of encoders. Each encoder receives Q, K, and V from the previous one. Within each encoder, there is a Multi-Head Attention unit (implementing Equation 2) and a Feed-Forward Network. The representation c generated by the last encoder is then sent to the decoder.
2.2.3. Decoders
A Decoder uses the vector c received from the Encoder layers to generate the translated sequence t. The layers of the decoder are configured similarly to the encoder concerning the pair of multi-head attention and feed-forward layers. In addition to these, the decoder has a third layer called Masked Multi-Head Attention, responsible for ensuring that the decoder obtains information only from the preceding terms in the sequence t to preserve the auto-regressive property [Vaswani et al., 2013].
2.2.4. Multi-Head Attention
In the so-called Multi-Head Attention, the Transformer projects the vectors Q, K, and V into multiple multi-heads with different learned linear projections. The resulting vectors are concatenated and projected again, resulting in the final vector representation, as depicted in Figure 7. Thus, the Transformer can pay attention to different representation subspaces at different positions [Vaswani et al., 2013], in addition to leveraging parallel computation.
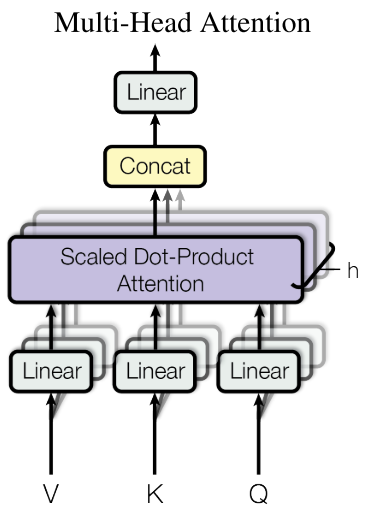 Figure 7: Schema of Multi-Head Attention. Source: [Vaswani et al., 2013].
Figure 7: Schema of Multi-Head Attention. Source: [Vaswani et al., 2013].
2.2.5. Transfer Learning
Through Transfer Learning techniques, a Transformer can be effectively applied to a range of NLP tasks, despite its initial design for sequence-to-sequence tasks. This versatility stems from the Transformer's capability to encode statistical patterns common to various NLP tasks into the matrices K, Q and V.
Fine-Tuning -- a form of transfer learning -- involves initial training on a source task $\tau_i$ followed by an adjustment of the learned parameters from $\tau_i$ to be applicable to solving a target task $\tau_j \neq \tau_i $ [Howard and Ruder, 2018]. Through fine-tuning, the parameters of the pre-trained model are easily adaptable to other NLP tasks. There are several approaches that implement fine-tuning, such as Google BERT [Devlin et al., 2018] and OpenAI GPT [Radford et al., 2018].
The reuse of knowledge acquired in performing a generic task was first studied in computer vision research and, with the advent of the Transformer, has been extensively investigated in NLP [Howard and Ruder, 2018]. One advancement in NLP was the realization that matrices K and V learned by the Transformer serve as a universal representation for textual constructs, capturing prominent syntactic and semantic aspects in the given textual construction. These aspects reveal idiosyncrasies embedded in the model during its training.
The neural memory of K and V embeds a Neural Language Model, which comprehends a new generation of Word Representations [Turian et al., 2010] (also known as Word Vectors, or Word Embeddings) for use in transfer learning across various work tasks. To our knowledge, the Transformer is currently the most robust and suitable model for pre-training these Language Models, which will be further explored in the next section.
3. Neural Language Models
This section discusses Language Models in the context of Neural Networks.
Given that each NLP task exhibits a distinct set of relevant features influencing its behavior and outcomes [Kubat, 2017], it is crucial to carefully select an appropriate set of features to represent sentences given as input to the algorithm that has been selected. This stage of feature definition, known as Feature Engineering, is one of the major challenges in developing machine learning algorithms [Kubat, 2017] and must be carefully conducted, as it has a significant impact on the algorithm's results. These features are typically stored in Feature Vectors.
In some cases, features are curated by experts, while in other scenarios features are collected through an automated process. Additionally, the criteria for feature selection are task-specific. For instance, in the case of Named Entity Recognition (NER), the features indicating whether a term should be considered a named entity encompass: term with the first letter capitalized, term preceded by a definite article, grammatical classes (e.g., noun, proper noun), prefixes and suffixes (e.g., diseases commonly ending with "it"), foreign words, term position within the sentence, term frequency in the training corpus, presence of other entities in the sentence, etc. [Nadeau and Sekine, 2007].
Feature engineering often deals with the presence of redundant features, and also with features that are important in a given context but may not be as relevant in other contexts, among other obstacles. As a result, feature engineering is typically a costly and time-consuming process.
There is a recent trend on using Word Representations to alleviate the burden of effort spent in the feature engineering phase, as they provide efficient text representations that enhance the performance of classification algorithms applied to NLP tasks. Indeed, this is a rapidly growing research area that has been experiencing intense development due to recent advances in Deep Learning methods and the increased capacity for parallel processing.
3.1. Word Vector Representation
Language models are also known as Large Language Models (LLM), Word Embeddings, Word Vectors, Feature Vectors or Word Representations [Bengio et al., 2000][Turian et al., 2010][Bojanowski et al., 2017].
A Word Vector is in summary a numeric vector used to represent a unit of text (which can be a word, a document, a paragraph, etc.) given as input to NLP algorithms. This computational representation of textual data serves as an alternative to hand-designed feature vectors generated during the initial feature engineering phase in classical NLP pipelines.
One of the pioneer models of word representation is the One-Hot Vector, which represents each word as a vector of size |W| (i.e., one vector dimension for each word in the vocabulary W) containing values of 1 in the dimension corresponding to the given word, while all other dimensions receive the value 0. Table 1 provides an example of a one-hot vector encoding for four words from a hypothetical vocabulary of size |V|=6.
 Table 1: One-hot representation.
Table 1: One-hot representation.
Unfortunately, the one-hot representation is inefficient due to its high dimensionality (one dimension for each word in the vocabulary) and its nature as a sparse matrix model, as each vector is composed of 0 values in most of its dimensions [Turian et al., 2010]. Distributional Representations are alternatives to mitigate these drawbacks.
Distributional Representations are generally based on matrices whose values are relative to the distribution of words in a specific context of that word. A context can be the entire document, a section of a document, other words nearby or around the word, among others. Typically, the context is defined in terms of window size and direction [Turian et al., 2010]. For instance, a context could be characterized by a window of the last 3 terms preceding each word, or a window of terms both to the left and right of each word.
In addition to the context, it is necessary to define the metrics to be used. One of the most common metrics is the co-occurrence of a pair of words, which can be recorded in a co-occurrence matrix of dimensions |W|*|W|. Another possibility is to use the widely adopted Term Frequency -- Inverse Document Frequency (TF-IDF), which measures how discriminative a word is in a given collection of documents, i.e., how frequent a word is in a given document while being rare in other documents in the collection.
These distributional representations are vectors that, based on the distributional hypothesis [Firth, 1957][Harris, 1954], contain contextual information generated through word counting, so that words occurring in the same contexts tend to have similar meanings [Baroni et al., 2014]. Such representations are suitable for tasks like classification and text retrieval; however, the challenge remains open to configure them appropriately for use in sequence labeling tasks (such as NER) [Turian et al., 2010].
An alternative approach involves generating representations through unsupervised training. These representations, commonly known as Distributed Representations, are typically induced using neural language models through training on a Language Modeling task. Unlike distributional representations that count the frequency of words in a given context, distributed representations are small – i.e., usually with a size between 50 and 1000 dimensions – and dense [Turian et al., 2010] – i.e., most dimensions contain values other than 0.
3.2. The Language Modeling Task
Language Modeling is an NLP task whose goal is to estimate the probability distribution of words in a given sentence. Traditionally, this estimation is achieved by predicting the next word based on the preceding words in the sentence [Collobert and Weston, 2008] using the chain rule of probability [Bengio, 2008]:
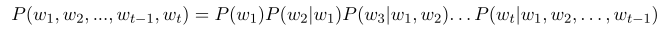 Equation 3: Chain rule of probability. Source: [Bengio, 2008].
Equation 3: Chain rule of probability. Source: [Bengio, 2008].
This equation predicts the probability that a word w will be used at position t following the previous words $w_{1}, w_{2}, ..., w_{t-1}$ in a given sentence. It is reasonable to expect that the term beach has a higher likelihood than the word jail of being the next word used in the sentence "I like to be in this…". Stated differently, a language model assesses the probability of a specified sentence existing within the modeled language [Huyen, 2019].
Neural language modeling produces a set of weights (i.e., parameters) that are incrementally adjusted to minimize the loss during network training. The adjusted weights are used to induce word embeddings, whose similarity to other embeddings in the vocabulary indicates that these words occur in similar contexts in the given training set [Jurafsky and Martin, 2019].
Neural language models implement a form of Unsupervised Learning and therefore do not require pre-labeled input data. The scarcity of manually annotated resources is a problem for Supervised Learning-based approaches, as is the case in many NLP algorithms, since generating pre-labeled data can be a costly and time-consuming task [Radford et al., 2018].
By using unsupervised learning, language models leverage the vast amount of unlabeled text available on the web, which is an immeasurable source of linguistic knowledge to be embedded in such models. Unsupervised training allows the model to automatically learn the latent features associated with syntactic and semantic properties.
There are many approaches to training language models, such as [Bengio et al., 2000][Collobert and Weston, 2008][Mikolov et al., 2013][Pennington et al., 2014][Bojanowski et al., 2017].
In a pioneering work, Bengio et al., 2000 proposed a distributed representation model that effectively overcame the problem known as the Curse of Dimensionality. This problem was a barrier to training language models using neural networks; in earlier models, each word in the vocabulary was treated as a random variable which resulted in a network with a massive number of parameters, making training computationally infeasible due to the high computational cost involved.
Collobert and Weston, 2008 introduced a convolutional neural network to jointly train various NLP tasks through semi-supervised learning. The approach combines unsupervised learning, specifically language modeling, with supervised learning of other tasks in the pipeline, such as NER, part-of-speech tagging, etc. Therefore, this work demonstrated how to utilize embeddings learned in an unsupervised manner in the training of supervised tasks, rather than manually designed features.
Mikolov et al., 2013 introduced Word2Vec, a language model with a simple and efficient neural network that has few hidden layers precisely to minimize the computational complexity caused by the non-linear hidden layer of deep neural network models. Word2Vec is provided in two similar versions: Continuous Bag-of-Words (CBOW), which predicts a target word based on the context words (4 words to the left and 4 words to the right) without considering the order of these words; and Continuous Skip-Gram, which predicts a target word based on another word within a specified range. Word2Vec captures different kinds of word similarity, going beyond basic syntax regularities. By employing simple algebraic operations on the word vectors, it is possible to observe that there is a similarity between the words big and bigger in the same way as between the words small and smaller. Notably, an intriguing outcome arises from the operation `$vector(King) - vector(Man) + vector(Woman) \approx vector(Queen)$.
Pennington et al., 2014 introduced the GloVe model (Global Vectors for Word Representation), which generates global vectors in the sense that they contain statistical information regarding the entire training corpus. It employs a hybrid approach that combines co-occurrence matrices with distributed representations.
Bojanowski et al., 2017 describe FastText as an extension of the Continuous Skip-Gram model that incorporates the morphological structure of words. It represents each word based on its internal sub-terms (e.g., the vector for the word where is generated by summing the vectors of the n-grams <wh, whe, her, ere, re>). Thus, FastText addresses the Out-of-Vocabulary (OoV) problem by enabling the representation of words not present in the training set.
The models presented up to this point are considered static embeddings [Ethayarajh, 2019][Kalyan et al., 2020][Tawfik et al., 2020], since they assign a unique representation to each word in the vocabulary, thereby limiting their ability to handle polysemy (when a word has different meanings depending on the context in which it appears).
3.3. Context-aware Models
Recent work has considered the so-called context-sensitive word representations [Ethayarajh, 2019]. These contextualized language models have dynamic representation spaces, so that a specific term can have different representations depending on the specifics of the text in which it is found.
For instance, the Embeddings from Language Models (ELMo) model [Peters et al., 2018]~\cite{} derives context from the internal states of a bidirectional LSTM network that traverses both the right and left contexts of the current term. ELMo concatenates the internal states of the two layers to produce context-sensitive embeddings from both directions.
The Generative Pre-trained Transformer (GPT) [Radford et al., 2018] applies the Transformer architecture to a Language Modeling task to pre-train universal embeddings adaptable to various NLP tasks—such as Natural Language Inference, Question-Answering, Semantic Similarity, and Text Classification—through Fine-Tuning. Both ELMo and GPT use unidirectional language models to learn to represent context. The bidirectional context created by ELMo is a concatenation of two unidirectional contexts learned by different networks.
The BERT (Bidirectional Encoder Representations from Transformers) language model [Devlin et al., 2018] employs the Transformer architecture to train on the Masked Language Modeling task -- a variation of the traditional Language Modeling seen in Equation 3. In this task, the model receives a training sentence with one of its terms hidden by a mask (e.g., "I like this [X] and ventilated room") and it must uncover the term hidden behind the mask. By accomplishing the task objective, the network generates a Bidirectional Context that incorporates information statistically relating each term within the sentence to all neighboring terms present in the sentence. The bidirectional context captures various facets and features — e.g., long-term dependencies, hierarchical relationships, sentiments — that are relevant to task completion [Howard and Ruder, 2018]. The awareness of the bidirectional context is a key aspect that enabled BERT to achieve the state of the art in 11 NLP tasks [Devlin et al., 2018].
3.4. Neural Models for Sentences
The arrival of word representations has inspired other approaches to generate vector representations for larger text segments, such as phrases, sentences, paragraphs, and even entire documents. Inspired by CBOW [Mikolov et al., 2013], the Sent2Vec model [Pagliardini et al., 2017] generates Sentence Vectors by averaging the vectors of the constituent n-grams in the input sentence. In fact, sentence vectors generated by averaging the vectors of all words in the sentence are quite robust models [Kenter et al., 2016].
Mikolov et al., 2013b propose a method for encoding idiomatic expressions, i.e., terms or phrases that have a meaning derived from the composition of their components, which is different from the meanings of the individual terms. For example, the expression Boston Globe represents the name of a newspaper, and its meaning is distinct from the simple combination of the individual terms Boston and Globe. Additionally, the article describes some interesting properties of the Skip-Gram model, such as the Additive Property, which yields semantically coherent results. For example, in the vector space produced by Skip-Gram, the result of vector(Russia) + vector(river) is close to vector(Volga River), while vector(Germany) + vector(capital) is close to vector(Berlin). Such observations suggest that it is possible to obtain a non-obvious understanding of language by using Vector Arithmetic on word vectors [Mikolov et al., 2013b].
Through a generalization of Skip-Gram, the SkipThought model [Kiros et al., 2015] encodes a sentence by predicting the surrounding sentences. SkipThought implements an encoder-decoder model: the encoder maps words to a sentence vector, which is then utilized by the decoder to predict the surrounding sentences.
The InferSent model [Conneau et al., 2017] employs a BiLSTM siamese network with a final layer of max-pooling. InterSent works as follows: the model is trained in a supervised fashion using the Stanford Natural Language Inference (SNLI) dataset [Bowman et al., 2015], surpassing the results of unsupervised methods such as Skip-Thought. The SNLI dataset comprises 570,000 sentence pairs annotated with labels contradiction, entailment, and neutral. InferSent results suggest that Natural Language Inference (NLI) is a highly suitable task for sentence embeddings training.
The Sentence-BERT (SBERT) model [Reimers and Gurevych, 2019] uses siamese and triplet networks (i.e., different networks with tied weights) to generate sentence embeddings. The training step of Sentence-BERT takes as input a pair of sentences and a similarity value between them. Initially, Sentence-BERT applies a pooling operation on the BERT embeddings to obtain a fixed-size representation (usually 768) for each sentence. As shown in Figure 8, in the end, a single fixed-size representation is generated based on the similarity between the two representations.
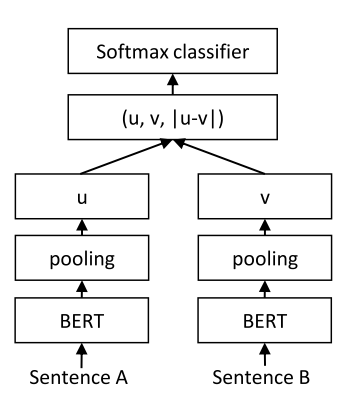 Figure 8: The architecture of the siamese network of SBERT. Source: [Reimers and Gurevych, 2019].
Figure 8: The architecture of the siamese network of SBERT. Source: [Reimers and Gurevych, 2019].
4. More recent NLP research
We have witnessed a heated research focus around the release of ChatGPT. The ChatGPT system uses the models of the GPT family – GPT-3 [Radford et al., 2018], GPT-4 [Achiam et al., 2023], etc – to perform text generation in a dialog style [Liu et al., 2023]. GPT is a decoder-only language model fine-tuned through Reinforcement Learning from Human Feedback [Tian et al., 2024].
Recent research focuses on increasing the network size by developing Large Language Models containing billions of parameters [Tian et al., 2024]. GPT-3 contains 175 billions of parameters, Llama 65 B [Touvron et al., 2023], Chinchilla 70 B, PaLM 540B, BLOOM 176B [Le et al., 2022]. Studies [Hoffmann et al., 2022][Touvron et al., 2023] have found not necessarily the larger model results to best performance at inference time, but there is a trade-off between the model and dataset sizes such that the best model would be a smaller model trained longer (i.e., on more samples).
A recent trend is to incorporate language models into larger systems. For example, DALL-E (https://openai.com/dall-e-3) is a system to generate images from text prompts [Betker et al., 2023]. Sora (https://openai.com/sora#research) is a system capable of generating high-fidelity videos from input text based on diffusion models [Peebles and Xie, 2023]. Gemini [Anil et al., 2023] is a multimodal model trained on different modalities of data such as image, audio, and video. However, some systems and applications lack academic references to describe the techniques employed and details of integrating the theoretical models in the systems. Usually, the implementation details are referred to in web pages. Many of the recent research on language models are described in technical reports uploaded to repositories which do not account for peer-review processes. This difficulties the scrutiny of the real advancements in this research area and the establishment of a reliable ground of scientific validation.
There are works focusing on demonstrating the linguistic capabilities of language models. The results of the study by Tenney et al., 2019, suggest that the initial layers of BERT networks concentrate on basic syntactic information, while the higher layers focus on high-level semantic information. Ettinger et al., 2020 applies tests based on psycholinguistic studies to assess the language models' ability to capture linguistic features. The results suggest that probability distributions are sensitive to linguistic distinctions, such as semantic roles, pragmatic reasoning, common sense, etc. These aspects would be evidence of idiosyncrasies embedded in the model during its training.
Diverse surveys aim to review the methods and techniques employed on the last released large language models. Other surveys [Xu et al., 2023][Lyu et al., 2024][Chang et al., 2023] address the evaluation of language models. The work of [Lyu et al., 2024] categorizes a bunch of methods for the evaluation of language models in terms of faithful explainability.
There are works analyzing the language capabilities of language models and comparing their procedures with the functioning of the human brain. For example, Sejnowski, 2023 hypothesized that the intelligence of language models is a mirror that reflects the intelligence of the person using such a system. The paper of Dodig, 2023 claims that, although GPT models lack mechanisms of consciousness from a cognitive science perspective, they have already passed the Turing test and therefore can successfully imitate human language capabilities.
However, there is neither consensus nor definition about which type of analysis should be employed to evaluate the language models. This state of affairs is perhaps not surprising, since neural networks are examples of Complex Systems [Scott, 1995] and therefore, are essentially holistic and interdisciplinary. Thus, neural networks for language models would be machines "as complex as the systems they model and therefore they will be equally difficult to analyse" [Scott, 1995]. This situation resembles the difficulty of validating models based on a relativist, holistic philosophy of science [Barlas and Carpenter, 1990]. By such approach the "The criterion of practical use has taken the place of formal rigor [...] validation becomes a semiformal, conversational process" than "a matter of formal accuracy". Therefore, the emergence of neural language models demand the research and development of new validation methods to assess their capacities, considering their holistic and interdisciplinary nature.
5. Critical Analysis
Up to this point, we concentrated on the Transformer and its capability to handle global context in input sequences. This advantage enables the Transformer to successfully train Language Models, leveraging huge amounts of data. However, there are open issues: (i) the difficulty to interpret [Lipton, 2023] the inner workings of neural networks, and consequently, of transformers; (ii) the distributed nature [Scott, 1995] of Language Models hinders control of the patterns represented (for example, societal biases [Silva et al., 2021]).
The Attention Mechanism and the Transformer model have elevated the state-of-the-art in various NLP tasks that have long been challenges in this research area. Such improvements suggest that a new level of language understanding can be achieved by using attention-based models to capture the patterns that structure textual sentences. The invention of attention-based language models can be stated as a revolution in the NLP research field, symbolizing a significant technological leap forward in this field. However, there are different perspectives regarding the actual advancements achieved in a scientific context beyond computer science.
In a position paper, Bender and Koller, 2020 argue that language models are not, a priori, capable of understanding the real meaning of processed texts, as they are trained only on textual forms (i.e., the linguistic signal). This is based on the definition of meaning as the relationship between a linguistic form and an intention of communication. This would imply that there is a portion of meaning attributed to extra-textual information not present in the training set. The authors draw attention to the imprudent use of certain terms (such as understanding, comprehension, etc.) as academic terminology when reporting research results in the field.
On the other hand, Sahlgren and Carlsson, 2021 argue that if meaning produces effects on form, then a language model should at least be able to observe and learn these effects.
This debate addresses issues that have historically been studied in various research areas. Therefore, it is necessary to analyze the results obtained by this so-called NLP revolution with caution, as it raises expectations and interests from different actors in society — companies, states, political groups, and even the public at large.
For example, AlphaFold [Alquraishi, 2019] is a Google project aimed at predicting the 3D structure of proteins -- an essential challenge within Biology [Callaway et al., 2020] -- using neural language models. These proteins could be applied in projects for new therapies for infectious diseases, less allergenic foods, and also for potential malicious applications—such as the development of toxic proteins as biological weapons [Vig et al., 2020]. There are also examples of work in Law [Chalkidis et al., 2020][Elwany et al., 2019] or in Geosciences and Petroleum Engineering [Massot, 2020]. The work [Mcguffie and Newhouse, 2020] warns about potential language models trained to generate content based on radical ideologies (white supremacy, anti-Semitism, etc.) with the aim of disseminating extremist thoughts.
Given that neural language models are trained to recognize prominent patterns in the training set, it is expected that they capture — and consequently reproduce — racist, classist, sexist, misogynistic, homophobic, xenophobic biases, and other patterns historically perpetuated in society. For example, the results from Silva et al., 2023 indicate that Transformers exhibit a statistically significant tendency to infer female and Afro-American subjects in contexts of emotive words, thus highlighting an embedded racial bias in these opaque-box models.
The existence of bias in neural models raises concerns, in particular in sensitive situations such as the development of methods for automatic student evaluation [Mayfield and Black, 2020], the classification of patients with Opioid Use Disorder using longitudinal health data [Fouladvand et al., 2021], or the exploration of the connection between cannabis use and depression disorder through Twitter post content [Yadav et al., 2021], and so on. Research applying language models to study such complex and interdisciplinary topics should take into account the knowledge and perspectives of other fields to avoid oversimplifications and the establishment of spurious correlations.
In this sense, it is crucial to address ethical issues in Artificial Intelligence. This includes implementing best practices for developing open-source Neural Language Models. This is essential to ensure individual freedom in an era where we store a multitude of personal information on the Internet. It also helps prevent the complexity [Assange et al., 2015] of this new technology from being used to mask biases and interests. Open-source code allows, to some extent, auditability of inferred classifications and coded rules, enabling the verification of results.
The introduction of machine learning algorithms everywhere, and NLP in particular, can impact the way we work, relate, learn, and develop. Therefore, there is a need for education at all levels aimed at teaching people how to use, understand, develop, and consume these tools in a healthy manner. Considering the breadth of the impacts that neural language models can have on human life, a pedagogical project is needed to guide towards a sustainable and ethical use of neural language models that also serve to address real and widely discussed societal problems, rather than solely serving the economic and market interests of the few who hold and dominate this technology.
6. Conclusions
The research efforts over the past decades on neural networks have led to the establishment of the Transformer model. A key aspect of the Transformer is its awareness of the global context within the training collection by "paying attention" to all the terms surrounding the current term being processed (not only to the n-grams to left or right as in the previously proposed approaches).
In this report, we reviewed the Transformer as a suitable approach to train Language Models that efficiently compress the global context of text collections by encoding the statistical patterns prominent in the language. Diverse long-standing NLP problems were suddenly solved by approaches applying transformers-based language models. This demonstrates and corroborates the impressive performance of Neural Language Models. Here we reviewed two of these tasks: Named Entity Recognition and Topic Modeling.
The arrival of neural language models shed many paths of discovery and improvements in processes, studies, and scientific discovery. Despite their undeniable success, the complexity and innovation of such technological tools raises concerns about: (i) evaluation of such models; and (ii) their ethical applicability -- as voted by the November 2021 Unesco Assembly [Unesco, 2021].
References
[1] C. Manning, H. Schütze, 1999, Foundations of statistical natural language processing, MIT press.
[2] Y. Barlas, S. Carpenter, 1900, Philosophical roots of model validation: two paradigms, Wiley Online Library.
[3] B. Goertzel, 2013, Chaotic logic: Language, thought, and reality from the perspective of complex systems science, Springer Science & Business Media.
[4] M. Kubat, 2017, An introduction to machine learning, Springer.
[5] C. Thrampoulidis, 2024, Implicit Bias of Next-Token Prediction, arXiv preprint.
[6] S. Ruder, 2019, Neural transfer learning for natural language processing, NUI Galway.
[7] J. Devlin, M. Chang, K. Lee, K. Toutanova, 2018, Bert: Pre-training of deep bidirectional transformers for language understanding, arXiv preprint.
[8] R. Pascanu, T. Mikolov, Y. Bengio, 2013, On the difficulty of training recurrent neural networks, International conference on machine learning.
[9] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, I. Polosukhin, 2017, Attention is all you need, arXiv preprint.
[10] I. Sutskever, O. Vinyals, Q. Le, 2014, Sequence to sequence learning with neural networks, Advances in neural information processing systems.
[11] S. Hochreiter, J. Schmidhuber, 1997, Long short-term memory, MIT Press.
[12] M. Luong, H. Pham, C. Manning, 2015, Effective approaches to attention-based neural machine translation, arXiv preprint.
[13] A. Galassi, M. Lippi, P. Torroni, 2020, Attention in natural language processing, IEEE Transactions on Neural Networks and Learning Systems.
[14] G. Kobayashi, T. Kuribayashi, S. Yokoi, K. Inui, 2020, Attention is Not Only a Weight: Analyzing Transformers with Vector Norms, Conference on Empirical Methods in Natural Language Processing (EMNLP).
[15] M. Geva, R. Schuster, J. Berant, O. Levy, 2020, Transformer feed-forward layers are key-value memories, arXiv preprint.
[16] S. Sukhbaatar, E. Grave, G. Lample, H. Jegou, A. Joulin, 2019, Augmenting self-attention with persistent memory, arXiv preprint.
[17] S. Tian, Q. Jin, L. Yeganova, P. Lai, Q. Zhu, X. Chen, Y. Yang, Q. Chen, W. Kim, D. Comeau, 2024, Opportunities and challenges for ChatGPT and large language models in biomedicine and health, Briefings in Bioinformatics.
[18] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, 2018, Improving language understanding with unsupervised learning, Technical report, OpenAI.
[19] J. Turian, L. Ratinov, Y. Bengio, 2010, Word representations: a simple and general method for semi-supervised learning, Annual Meeting of the Association for Computational Linguistics.
[20] J. Howard, S. Ruder, 2018, Universal language model fine-tuning for text classification, arXiv preprint.
[21] D. Nadeau, S. Sekine, 2007, A survey of named entity recognition and classification, Lingvisticae Investigationes.
[22] R. Collobert, J. Weston, 2008, A unified architecture for natural language processing: Deep neural networks with multitask learning, International Conference on Machine Learning.
[23] Y. Bengio, 2008, Neural net language models, Scholarpedia.
[24] C. Huyen, 2019, Evaluation Metrics for Language Modeling, The Gradient.
[25] D. Jurafsky, J. Martin, 2000, Speech and Language Processing. An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, MIT Press.
[26] Y. Bengio, R. Ducharme, P. Vincent, C. Janvin, 2003, A neural probabilistic language model, The Journal of Machine Learning Research.
[27] T. Mikolov, K. Chen, G. Corrado, J. Dean, 2013, Efficient estimation of word representations in vector space, arXiv preprint.
[28] J. Pennington, R. Socher, C. Manning, 2014, Glove: Global vectors for word representation, Conference on Empirical Methods in Natural Language Processing (EMNLP).
[29] P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, 2017, Enriching word vectors with subword information, Transactions of the Association for Computational Linguistics.
[30] K. Ethayarajh, 2019, How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings, Transactions of the Association for Computational Linguistics.
[31] K. Kalyan, S. Sangeetha, 2020, Secnlp: A survey of embeddings in clinical natural language processing, Journal of Biomedical Informatics.
[32] N. Tawfik, M. Spruit, 2020, Evaluating sentence representations for biomedical text: Methods and experimental results, Journal of Biomedical Informatics.
[33] M. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, L. Zettlemoyer, 2018, Deep contextualized word representations, arXiv preprint.
[34] M. Pagliardini, P. Gupta, M. Jaggi, 2017, Unsupervised learning of sentence embeddings using compositional n-gram features, arXiv preprint.
[35] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, 2013, Distributed representations of words and phrases and their compositionality, Advances in Neural Information Processing Systems.
[36] R. Kiros, Y. Zhu, R. Salakhutdinov, R. Zemel, R. Urtasun, A. Torralba, S. Fidler, 2015, Skip-thought vectors, Advances in Neural Information Processing Systems.
[37] R. Kiros, Y. Zhu, R. Salakhutdinov, R. Zemel, R. Urtasun, A. Torralba, S. Fidler, 2017, Supervised learning of universal sentence representations from language inference data, arXiv preprint.
[38] S. Bowman, G. Angeli, C. Potts, C. Manning, 2015, A large annotated corpus for learning natural language inference, arXiv preprint.
[39] N. Reimers, I. Gurevych, 2019, Sentence-bert: Sentence embeddings using siamese bert-networks, arXiv preprint.
[40] C. Jonquet, N. Shah, C. Youn, M. Musen, C. Callendar, M. Storey, 2009, NCBO annotator: semantic annotation of biomedical data, International Semantic Web Conference.
[41] T. Berners-Lee, J. Hendler, O. Lassila, 2001, The Semantic Web, Scientific American.
[42] Z. Miftahutdinov, A. Kadurin, R. Kudrin, E. Tutubalina, 2021, Drug and disease interpretation learning with biomedical entity representation transformer, arXiv preprint.
[43] R. Doğan, R. Leaman, Z. Lu, 2014, NCBI disease corpus: a resource for disease name recognition and concept normalization, Journal of Biomedical Informatics.
[44] M. Basaldella, F. Liu, E. Shareghi, N. Collier, 2020, COMETA: A corpus for medical entity linking in the social media, arXiv preprint.
[45] E. Choi, O. Levy, Y. Choi, L. Zettlemoyer, 2018, Ultra-fine entity typing, arXiv preprint.
[46] E. Alsentzer, J. Murphy, W. Boag, W. Weng, D. Jin, T. Naumann, M. McDermott, 2019, Publicly available clinical BERT embeddings, arXiv preprint.
[47] J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. So, J. Kang, 2020, BioBERT: a pre-trained biomedical language representation model for biomedical text mining, Bioinformatics.
[48] L. Akhtyamova, P. Martínez, K. Verspoor, J. Cardiff, 2020, Testing contextualized word embeddings to improve NER in Spanish clinical case narratives, IEEE Access.
[49] Y. Lyu, J. Zhong, 2021, DSMER: A Deep Semantic Matching Based Framework for Named Entity Recognition, European Conference on Information Retrieval.
[50] D. Kim, J. Lee, C. So, H. Jeon, M. Jeong, Y. Choi, W. Yoon, M. Sung, J. Kang, 2019, A neural named entity recognition and multi-type normalization tool for biomedical text mining, IEEE Access.
[51] D. Cook, M. Triola, 2009, Virtual patients: a critical literature review and proposed next steps, Medical Education.
[52] K. Freeman, S. Thompson, E. Allely, A. Sobel, S. Stansfield, W. Pugh, 2001, A virtual reality patient simulation system for teaching emergency response skills to US Navy medical providers, Prehospital and Disaster medicine.
[53] T. Călinici, V. Muntean, 2010, Open labyrinth--a web application for medical education using virtual patients, Applied Medical Informatics.
[54] A. Takeuchi, T. Kobayashi, M. Hirose, T. Masuda, T. Sato, I. Ikeda, 2012, Arterial pulsation on a human patient simulator improved students’ pulse assessment, Journal of Biomedical Science and Engineering.
[55] T. Chaplin, B. Thoma, A. Petrosoniak, K. Caners, T. McColl, C. Forristal, C. Dakin, J. Deshaies, E. Raymond-Dufresne, M. Fotheringham, 2020, Simulation-based research in emergency medicine in Canada: priorities and perspectives, Journal of the Canadian Association of Emergency Physicians.
[56] I. Hege, A. Kononowicz, M. Adler, 2017, A clinical reasoning tool for virtual patients: design-based research study, JMIR Medical Education.
[57] E. Dafli, P. Antoniou, L. Ioannidis, N. Dombros, D. Topps, P. Bamidis, 2015, Virtual patients on the semantic Web: a proof-of-application study, Journal of Medical Internet Research.
[58] D. Blei, A. Ng, M. Jordan, 2003, Latent Dirichlet Allocation, The Journal of Machine Learning Research.
[59] T. Griffiths, M. Steyvers, J. Tenenbaum, 2007, Topics in semantic representation, Psychological Review.
[60] D. Mimno, H. Wallach, E. Talley, M. Leenders, A. McCallum, 2011, Optimizing semantic coherence in topic models, Conference on Empirical Methods in Natural Language Processing.
[61] A. Hoyle, P. Goel, A. Hian-Cheong, D. Peskov, J. Boyd-Graber, P. Resnik, 2021, Is Automated Topic Model Evaluation Broken? The Incoherence of Coherence, Advances in Neural Information Processing Systems.
[62] M. Grootendorst, 2022, BERTopic: Neural topic modeling with a class-based TF-IDF procedure, arXiv preprint.
[63] D. Angelov, 2020, Top2vec: Distributed representations of topics, arXiv preprint.
[64] J. Boyd-Graber, Y. Hu, D. Mimno, 2017, Applications of topic models, Foundations and Trends® in Information Retrieval.
[65] G. Bouma, 2009, Normalized (pointwise) mutual information in collocation extraction, Biennial GSCL Conference.
[66] A. Dieng, F. Ruiz, D. Blei, 2020, Topic modeling in embedding spaces, Transactions of the Association for Computational Linguistics.
[67] L. Thompson, D. Mimno, 2020, Topic modeling with contextualized word representation clusters, arXiv preprint.
[68] N. Peinelt, D. Nguyen, M. Liakata, 2020, tBERT: Topic models and BERT joining forces for semantic similarity detection, Annual Meeting of the Association for Computational Linguistics.
[69] H. Zhao, D. Phung, V. Huynh, Y. Jin, L. Du, W. Buntine, 2021, tBERT: Topic models and BERT joining forces for semantic similarity detection, arXiv preprint.
[70] M. Asgari-Chenaghlu, M. Feizi-Derakhshi, M. Balafar, C. Motamed, 2021, TopicBERT: A cognitive approach for topic detection from multimodal post stream using BERT and memory--graph, Chaos, Solitons & Fractals.
[71] A. Kulkarni, A. Hengle, P. Kulkarni, M. Marathe, 2021, Cluster Analysis of Online Mental Health Discourse using Topic-Infused Deep Contextualized Representations, International Workshop on Health Text Mining and Information Analysis.
[72] J. Kim, D. Kim, S. Kim, A. Oh, 2012, Modeling topic hierarchies with the recursive chinese restaurant process, International Conference on Information and Knowledge Management.
[73] M. Isonuma, J. Mori, D. Bollegala, I. Sakata, 2020, Tree-structured neural topic model, Annual Meeting of the Association for Computational Linguistics.
[74] H. Yan, L. Gui, Y. He, 2022, Hierarchical interpretation of neural text classification, Computational Linguistics.
[75] Y. Liu, T. Han, S. Ma, J. Zhang, Y. Yang, J. Tian, H. He, A. Li, M. He, Z. Liu, 2023, Summary of chatgpt-related research and perspective towards the future of large language models, Meta-Radiology.
[76] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, 2023, Gpt-4 technical report, arXiv preprint.
[77] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, 2023, Llama: Open and efficient foundation language models, arXiv preprint.
[78] T. Le Scao, A. Fan, C. Akiki, E. Pavlick, S. Ilić, D. Hesslow, R. Castagné, A. Luccioni, F. Yvon, M. Gallé, 2022, Bloom: A 176b-parameter open-access multilingual language model, arXiv preprint.
[79] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. Casas, L. Hendricks, J. Welbl, A. Clark, 2022, Training compute-optimal large language models, arXiv preprint.
[80] J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y. Guo, 2023, Improving image generation with better captions, Computer Science.
[81] W. Peebles, S. Xie, 2023, Scalable diffusion models with transformers, International Conference on Computer Vision.
[82] R. Anil, S. Borgeaud, Y. Wu, J. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. Dai, A. Hauth, 2023, Gemini: a family of highly capable multimodal models, arXiv preprint.
[83] I. Tenney, P. Xia, B. Chen, A. Wang, A. Poliak, R. McCoy, N. Kim, B. Van Durme, S. Bowman, D. Das, 2019, What do you learn from context? probing for sentence structure in contextualized word representations, arXiv preprint.
[84] A. Ettinger, 2020, What BERT is not: Lessons from a new suite of psycholinguistic diagnostics for language models, Transactions of the Association for Computational Linguistics.
[85] F. Xu, Q. Lin, J. Han, T. Zhao, J. Liu, E. Cambria, 2023, Are large language models really good logical reasoners? a comprehensive evaluation from deductive, inductive and abductive views, arXiv preprint.
[86] Q. Lyu, M. Apidianaki, C. Callison-Burch, 2024, Towards faithful model explanation in nlp: A survey, Computational Linguistics.
[87] Y. Chang, X. Wang, J. Wang, Y. Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y. Wang, 2023, A survey on evaluation of large language models, Transactions on Intelligent Systems and Technology.
[88] T. Sejnowski, 2023, Large language models and the reverse turing test, Neural Computation.
[89] G. Dodig-Crnkovic, 2023, How GPT Realizes Leibniz’s Dream and Passes the Turing Test without Being Conscious, Computer Sciences & Mathematics Forum.
[90] S. Scott, 2023, Approaching complexity, Faraday Discussions.
[91] A. Silva, P. Tambwekar, M. Gombolay, 2021, Towards a comprehensive understanding and accurate evaluation of societal biases in pre-trained transformers, Conference of the North American Chapter of the Association for Computational Linguistics.
[92] E. Bender, A. Koller, 2020, Climbing towards NLU: On meaning, form, and understanding in the age of data, Annual Meeting of the Association for Computational Linguistics.
[93] M. Sahlgren, F. Carlsson, 2021, The singleton fallacy: Why current critiques of language models miss the point, Frontiers in Artificial Intelligence.
[94] M. AlQuraishi, 2019, AlphaFold at CASP13, Bioinformatics.
[95] J. Vig, A. Madani, L. Varshney, C. Xiong, R. Socher, N. Rajani, 2020, Bertology meets biology: Interpreting attention in protein language models, arXiv preprint.
[96] I. Chalkidis, M. Fergadiotis, P. Malakasiotis, N. Aletras, I. Androutsopoulos, 2020, LEGAL-BERT: The muppets straight out of law school, arXiv preprint.
[97] E. Elwany, D. Moore, G. Oberoi, 2019, Bert goes to law school: Quantifying the competitive advantage of access to large legal corpora in contract understanding, arXiv preprint.
[98] J. Massot, 2020, How Named Entity Recognition and Document Comprehension Unlock Geosciences and Engineering Semantic Search without Big Data, EAGE Digitalization Conference and Exhibition.
[99] E. Mayfield, A. Black, 2020, Should you fine-tune BERT for automated essay scoring?, Workshop on Innovative Use of NLP for Building Educational Applications.
[100] S. Fouladvand, J. Talbert, L. Dwoskin, H. Bush, A. Meadows, L. Peterson, R. Kavuluru, L. Chen, 2021, Predicting Opioid Use Disorder from Longitudinal Healthcare Data using Multi-stream Transformer, arXiv preprint.
[101] S. Yadav, U. Lokala, R. Daniulaityte, K. Thirunarayan, F. Lamy, A. Sheth, 2021, When they say weed causes depression, but it’s your fav antidepressant”: Knowledge-aware Attention Framework for Relationship Extraction, PloS one.
[102] M. Baroni, G. Dinu, G. Kruszewski, 2014, Don’t count, predict! a systematic comparison of context-counting vs. context-predicting semantic vectors, Annual Meeting of the Association for Computational Linguistics.
[103] K. McGuffie, A. Newhouse, 2020, The radicalization risks of GPT-3 and advanced neural language models, arXiv preprint.
[104] S. Šuster, W. Daelemans, 2018, Clicr: A dataset of clinical case reports for machine reading comprehension, arXiv preprint.
[105] Unesco Assembly, 2021, Ethics of Artificial Intelligence - a Unesco Recommendation, UNESCO.
[104] Bengio, Y. and Ducharme, R. and Vincent, P., 2000, A Neural Probabilistic Language Model, Advances in Neural Information Processing Systems.